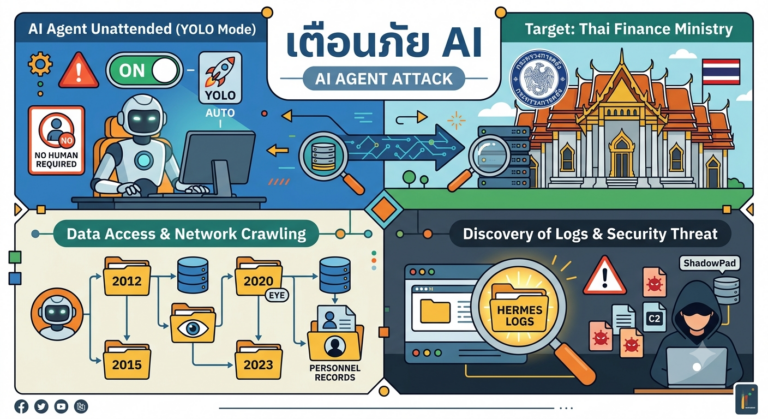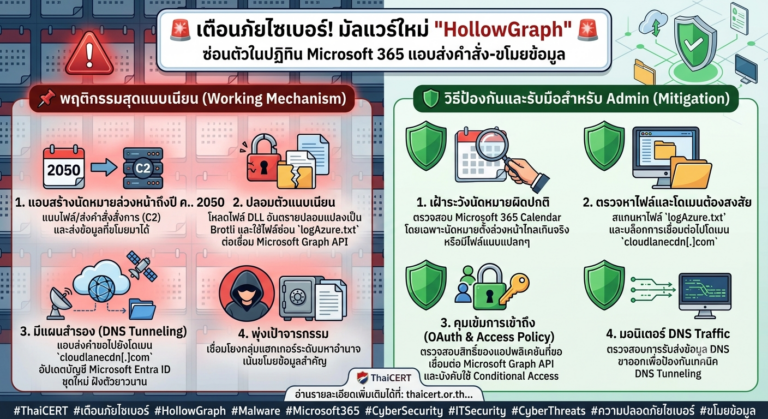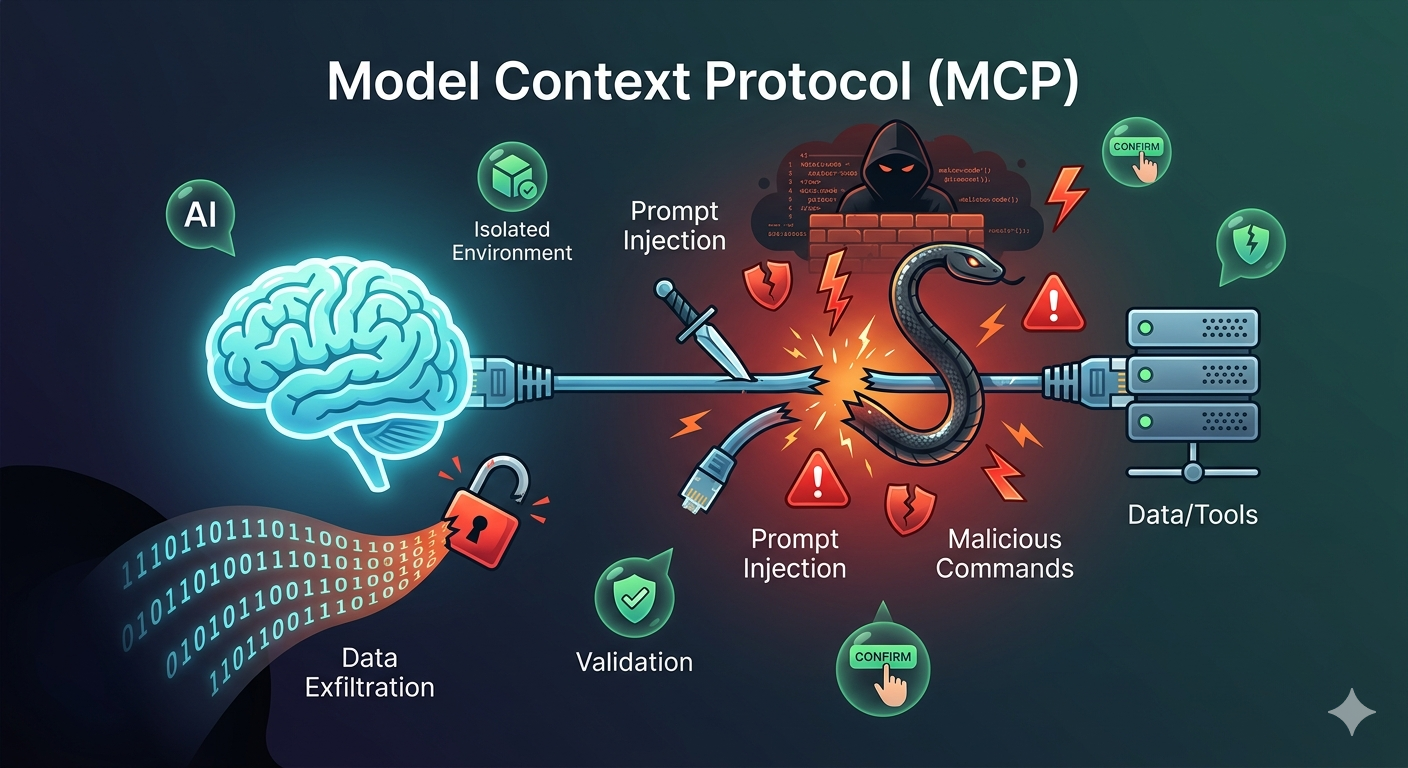
🛡️ ช่องโหว่ใหม่ใน Anthropic MCP: เมื่อ “ตัวเชื่อม” กลายเป็น “ทางเข้า” ของแฮกเกอร์!
กลายเป็นประเด็นใหญ่ในวงการ AI เมื่อมีการค้นพบช่องโหว่ด้านการออกแบบ (Design Vulnerability) ใน Model Context Protocol (MCP) ของ Anthropic ซึ่งเป็นโปรโตคอลที่ช่วยให้ AI สามารถเชื่อมต่อกับข้อมูลและเครื่องมือภายนอกได้
🔍 เกิดอะไรขึ้น?
ปกติแล้ว MCP ถูกสร้างมาเพื่อให้ AI อย่าง Claude สามารถ “คุย” กับฐานข้อมูลหรือแอปพลิเคชันของคุณได้โดยตรง แต่ช่องโหว่นี้เปิดโอกาสให้ผู้ไม่หวังดีใช้เทคนิค Prompt Injection เข้ามาควบคุมการทำงานของ MCP Server
อธิบายง่ายๆ คือ:
แฮกเกอร์ส่งคำสั่งแสบๆ ฝังไว้ในข้อมูลที่ AI ต้องไปอ่าน
เมื่อ AI อ่านข้อมูลนั้น ตัว MCP จะถูกสั่งให้รันคำสั่งอันตราย (Malicious Commands)
ผลที่ตามมาอาจเป็นการขโมยข้อมูล (Data Exfiltration) หรือการเข้าถึงระบบภายในที่ควรจะปลอดภัย
⚠️ ทำไมเรื่องนี้ถึงน่ากังวล?
Trust Overload: เรามักเชื่อใจว่า AI จะทำตามคำสั่งเราเท่านั้น แต่ MCP อาจถูกหลอกให้ทำตามคำสั่ง “แฝง” จากแหล่งข้อมูลภายนอก
System Access: MCP มักได้รับสิทธิ์ในการเข้าถึงไฟล์หรือฐานข้อมูลสำคัญ หากคุมไม่อยู่ ระบบทั้งหมดก็เสี่ยง
Shadow AI: หลายองค์กรเริ่มนำ MCP ไปใช้โดยที่ยังไม่มีมาตรการตรวจสอบความปลอดภัยที่เข้มงวดพอ
💡 แนวทางป้องกันเบื้องต้น
Sandboxing: รัน MCP Server ในสภาพแวดล้อมที่จำกัดสิทธิ์ (Isolated Environment)
Human-in-the-loop: อย่าปล่อยให้ AI ตัดสินใจรันคำสั่งสำคัญหรือส่งข้อมูลออกภายนอกโดยไม่มีการกดยืนยันจากคน
Input Validation: ตรวจสอบและกรองข้อมูลที่ AI ไปดึงมาจากแหล่งภายนอกเสมอ
#CyberSecurity #AI #Anthropic #MCP #TechNews #ช่องโหว่AI #ความปลอดภัยไซเบอร์